10.7 Reference Documentation
LLM Evaluation Dashboards
- LMSYS Chatbot Arena: Community-driven Evaluation for Best LLM and AI chatbots
- Vellum LLM Comparison Board
- The Berkeley Function/Tool Calling Leaderboard: evaluates the LLM's ability to call functions (aka tools) accurately. This leaderboard consists of real-world data and will be updated periodically.
- Galileo Agent Leaderboard: LLM Performance in Agentic scenarios. Version 2 is also available.
Evaluation Benchmarks
- VisualWebArena: for multimodal agents
- GAIA: HF Benchmarking General AI Agents
- OSWorld Benchmark for Multimodal Agents: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments
- SWE-Bench: dataset that tests systems' ability to solve GitHub issues automatically.
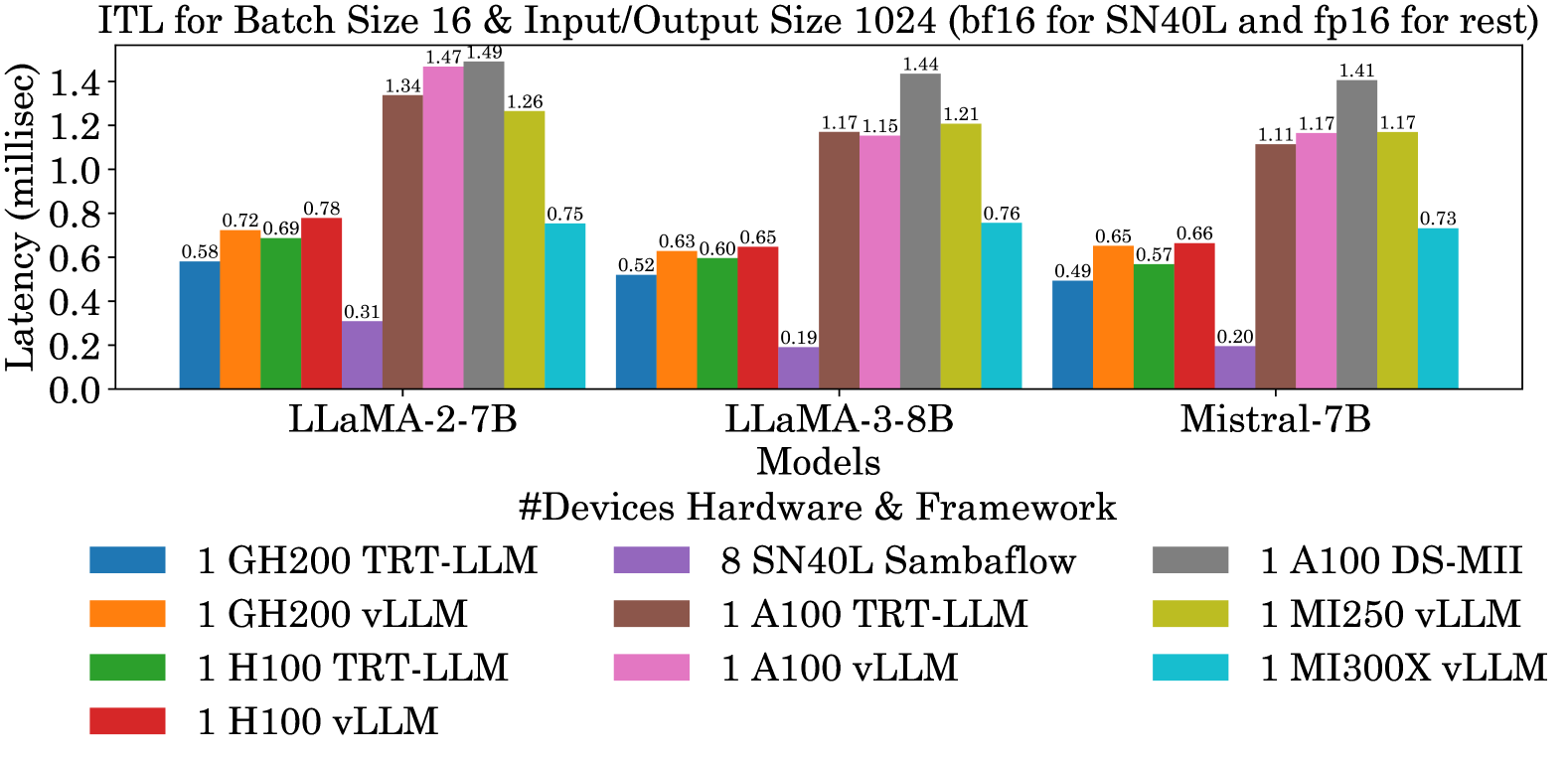
LLM Inference Benchmarks Research
- Inference Benchmarking of Large Language Models on AI Accelerators: LLM-Inference-Bench, a comprehensive benchmarking suite that evaluates the inference performance of the variety of llama-style LLMs across SOTA AI accelerators